Data Pre-processing text analysis using Orange tool.

Dataset Description:
Name: Red Wine Quality
This datasets is related to red variants of the Portuguese "Vinho Verde" wine.
Columns:
1 - fixed acidity
2 - volatile acidity
3 - citric acid
4 - residual sugar
5 - chlorides
6 - free sulfur dioxide
7 - total sulfur dioxide
8 - density
9 - pH
10 - sulphates
11 - alcohol
12 - quality (score between 0 and 10)

Now we will perform different pre-processing techniques using orange tool.
1. Discretization

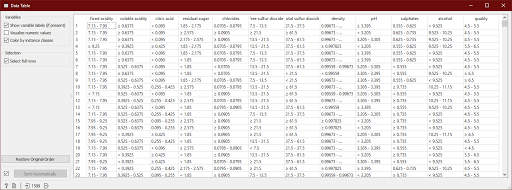
Output of discretization.


4. Normalization using python script.
from Orange.data import Table
from Orange.preprocess import Normalize
data = in_data
normalizer = Normalize(norm_type=Normalize.NormalizeBySpan)
out_data = normalizer(data)

Output of python script
Performing Sentiment Analysis Using Orange Tool:

Dataset Description:
#SaveBirdsandAnimal tweets

Data fetching using the token and secret key on topic save birds and animal.

Workflow with twitter widget to extract tweets and preprocess text to clean that data

Applying various text pre-processing techniques

Using widget Word cloud cloud to see most used words in our corpus

Using Sentiment Analysis widget with Liu Hu method

Output using Liu Hu method
In Liu Hu method a positive tweet is given a +ve score, neutral is given score 0 and negative tweet is given a -ve score.
No comments:
Post a Comment